

The world runs on data – and it’s running faster and faster.
Over 90% of the data in the world was generated over the past two years. Each day, 2.5 quintillion bytes of data are created. This is more than a rising tide. It’s a tidal wave. The businesses that ride the wave effectively will be the ones that thrive over the next decade.
And riding the wave of big data will require efficient and effective data ingestion.
At StarQuest, we provide enterprise organizations like US Foods, Mazda, and BlueCross BlueShield with data services for databases, data warehouses and big data platforms. If you’re looking for data ingestion to capitalize on your organization’s data, get in touch with us to see a free demo of our solutions.
If you’re looking to learn more about data ingestion, keep reading. On this page, we’ll unpack answers to some of the most common data ingestion questions so that you can have a fuller understanding of what the process entails – and how your organization can benefit from it.
We’ll cover topics like:
- What is data ingestion?
- What’s a good framework for data ingestion?
- Data ingestion vs. ETL – what’s the difference?
- How to build a data ingestion pipeline
- The top data ingestion tools in 2021
- How to ingest data from Db2
- How to ingest data from Azure
- How to ingest data from AWS
- How to get started with data ingestion
After reading, you should have a high-level understanding of data ingestion, and, if necessary, information on the first steps toward implementation of a data ingestion pipeline in your context.
To implement data ingestion for your use case now, get in touch with us. To learn more, keep reading.
Let’s dive in.
What is data ingestion?
Let’s start with the basics and define our term. What is data ingestion?
The term is fairly obvious when it’s broken into its component parts. Data is “information in digital form that can be transmitted or processed.” Ingestion is “the process of absorbing information.” So, data ingestion is the process of absorbing digital information that can be transmitted or processed.
That’s the essence of the term, but, in a tactical business sense, it involves a bit more. Here’s how Tech Target defines data ingestion: “Data ingestion is the process of obtaining and importing data for immediate use or storage in a database.”
Stitch goes into even more detail: “Data ingestion is the transportation of data from assorted sources to a storage medium where it can be accessed, used, and analyzed by an organization. The destination is typically a data warehouse, data mart, database, or a document store. Sources may be almost anything — including SaaS data, in-house apps, databases, spreadsheets, or even information scraped from the internet.”
The Purpose of Data Ingestion
Ingestion is used to synthesize multiple data sources into a single place of access. It’s meant to eradicate data silos. As the business definitions of the term make clear, data ingestion, in practicality, is more than absorption – it’s absorption plus configuration for storage or immediate use.
For instance: a business might need to report on customer data. But different customer data might be collected or stored in different systems. Maybe purchase data is stored in one database, while service request data is stored in another. In order to get a full picture of customer activity, a centralized database is needed, with data from all sources factored in. To set this up would require data ingestion.
That’s just one use case. Data ingestion is helpful in any scenario where multiple streams of data need to be synthesized into a single source.
What is a good framework for data ingestion?
With data ingestion defined, let’s examine how it works. There are three major approaches to the process, and, depending on the business needs that are involved, any of them can be “good”; a good data ingestion framework helps the business to reliably meet its data needs.
The three methods of data ingestion are batch processing, real-time processing, and micro batching.
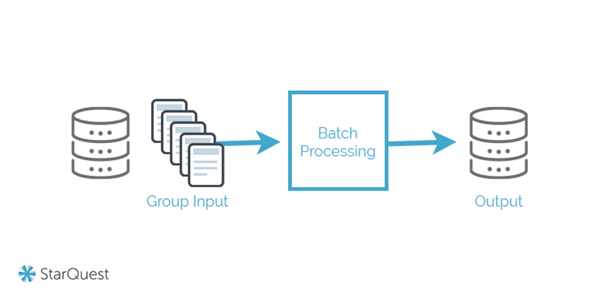
Batch Processing
This is the most common framework of data ingestion. It involves an ingestion layer that periodically collects and groups source data, then sends it in batches to the destination system. This may happen on a schedule, or with the activation of certain conditions. Batch processing is a good approach when a real-time data refresh isn’t required, because it tends to be more cost-efficient than the other approaches. But it can also be somewhat cumbersome – it usually involves multiple steps to export, import, and verify data, all of which can require a hands-on approach from IT.
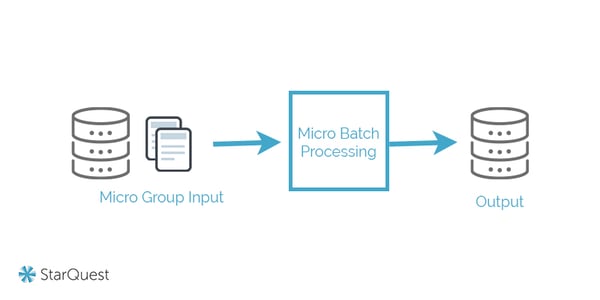
Micro Batching
Micro batching is a second approach to data ingestion. It functions in essentially the same way as batching, but it works with smaller ingested data groups to make data more current. While there’s some argument as to whether or not this approach falls under a wholly different category, in tactical terms, it is a middle ground between real-time and batch processing frameworks as it offers close to real-time data access without the requirement to process each update individually.
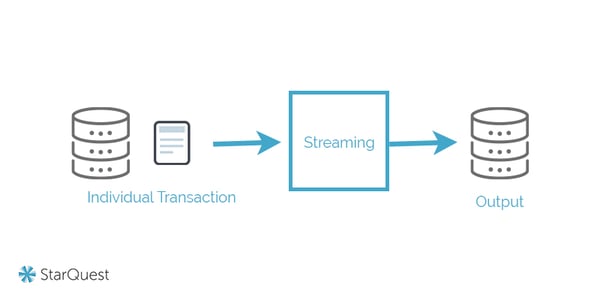
Real-Time Processing
Finally, real-time processing (or streaming) is a third framework for use cases where data must be as up to date as possible. Most often, this is the best approach to ingestion. A streaming approach loads data as soon as it’s recognized by the data ingestion layer. It tends to be more complex; to ensure accuracy and reliability, sources must be continually monitored for new information. It’s commonly used for predictive analytic purposes.
Data ingestion vs. ETL – what’s the difference?
With common approaches to data ingestion covered, let’s dive a little bit deeper and tackle a common question: What is ETL? And how is it related to or different from data ingestion?
The answer can be traced back to database processing protocols from the 1970s. Back then, storing data required extraction, transformation, and loading – or, in acronym form, ETL. Extract denotes the collection of data. Transform denotes processes that are performed on that data to configure it for usefulness or storage. This traditionally happens in a staging area outside of the data warehouse. Finally, load denotes the sending of processed data to a destination (usually a data warehouse or data lake).
So, technically, ETL is data ingestion – or at least one method of data ingestion.
The confusion around the term stems from the fact that, more recently, cloud computing has made it possible to flip the final two stages so that loading happens before transformation. This is known as ELT.
What Is ELT?
In ELT, transformation happens in the data warehouse itself; when it’s queried, data is transformed for usability and served accordingly. This eliminates the need for a staging area outside of the data warehouse, and it also makes the process of loading data quicker, because transformation doesn’t have to happen before data can be loaded.
The Takeaway
Both ETL and ELT are still viable methods of data ingestion, depending on your business needs. If you need a well-defined data workflow, ETL may make more sense. If you have huge amounts of unstructured data that could be queried in many different ways, you may consider ELT.
How to build a data ingestion pipeline
To implement data ingestion, you’ll need to build a data pipeline.
A data pipeline is a means of transporting raw data from SaaS platforms, databases, and any other sources into data warehouses or lakes. Basically, it’s the architecture of data ingestion. To build your pipeline effectively, here’s what you’ll need to consider.
1. What data sources and objects will be included?
This is the starting point: The data itself. You don’t need a data pipeline unless you have disparate data sources. Structuring your pipeline effectively starts with identifying what will be going into it.
Additionally, you’ll want to make sure that only the relevant objects are included in your data ingestion. For example, not every table, index, or constraint defined in an operational data store (ODS) is necessary in a data warehouse. In general, an ODS may have many tables that are temporary in nature and purpose related – and are not part of normal query processing. As a rule, such tables should not be migrated.
2. How close to real-time must the process be?
A second key consideration is the required time-relevancy of data. This will impact the type of ingestion you use (batch processing, micro batching or streaming), shaping the way the ingestion layer performs.
3. What format should the data be in?
Finally, your pipeline will be shaped by your expected output. How will data be configured in your end destination?
At a fundamental level, building your data pipeline requires considering what goes into the system, what happens in the system, and what comes out.
What are the top data ingestion tools?
The above specifications will help you to shape your data ingestion pipelines – but to build it, you’ll almost certainly use data ingestion tools that will power the process.
With that in mind, let’s take a look at four of the top data ingestion tools on the market today.
1. StarQuest Data Replicator
Admittedly, we’re a little biased. But we believe that our data ingestion software is the best on the market for a variety of enterprise data ingestion needs.
StarQuest Data Replicator (SQDR) sits between source and destination databases, allowing for real-time replication, vendor-agnostic heterogeneous DMBS pairings, and relational and NoSQL database compatibility using an intuitive GUI.
Notably, SQDR has a near-zero footprint on production servers. It’s also built to automatically restore replication following connectivity loss, without processes being compromised (something that is a struggle for other solutions).
Finally, SQDR typically allows for cost-savings of up to 90% when compared against our competitors. This is due to our per-core pricing model and our tailored implementations that are designed to meet your requirements (not to sell you services you don’t need).
To learn more about how SQDR can serve your organization’s data ingestion requirements, get in touch with us to schedule a free demo.
2. IMB InfoSphere Data Replication
IBM is, of course, an old industry stand-by. Nobody’s ever been fired for hiring this Fortune 500 company, or so the saying goes.
Here’s how they describe their data replication offering:
“IBM® InfoSphere® Data Replication provides log-based change data capture with transactional integrity to support big data integration and consolidation, warehousing and analytics initiatives at scale.”
While the solution is designed for multi-source, target and replication topology support, its tightest compatibility is with IBM’s Db2.
3. Oracle GoldenGate
Oracle is another Fortune 500 firm that’s well known for offering reliable computing solutions. Their solution in the data ingestion space is Oracle GoldenGate. Here’s how the company describes the solution:
“Oracle GoldenGate is a comprehensive software package for real-time data integration and replication in heterogeneous IT environments. The product set enables high availability solutions, real-time data integration, transactional change data capture, data replication, transformations, and verification between operational and analytical enterprise systems.”
Obviously, GoldenGate’s biggest benefit is its tight integration with Oracle Database, but it is built for heterogeneous data transfer. Like IBM, Oracle is a worthwhile solution to consider if cost-efficiency isn’t a high priority.
4. HVR Software
HVR Software is a newer solution. Originally, the company specialized in Oracle database ingestion and replication, but the solution has grown to encompass all of the industry-standard platforms (which you can view on their homepage). Here’s how they describe their capabilities on their website:
“[It’s] everything you need for efficient high-volume data replication and integration, whether you need to move your data between databases, to the cloud, or multi-cloud integration, into a data lake or data warehouse.”
If you’re considering investing in a data ingestion option that’s limited to cloud environments, HVR Software may make your list.
With these tools considered, let’s get deeper into the weeds of data ingestion. It’s time to look at a few common data sources and present best-practice approaches for ingestion.
How to ingest data from Db2
Let’s start with Db2, the long-standing relational database proprietary to IBM.
It’s worth noting that a search for “Db2 ingest” will turn up information on the platform’s INGEST command. This command is built to facilitate ingestion from an input file or pipe into a Db2 table. It is not what we’ll be dealing with here – the ingestion of data from Db2 for use in another destination.
For these purposes, we recommend SQDR, our data ingestion offering, as the best solution. SQDR can replicate data unidirectionally or bidirectionally between Oracle, Db2, Informix, Microsoft SQL Server, MySQL, Big Data stores, and more.
Whether you’re populating data to another Db2 environment or to an additional system, the process can be easily facilitated.
How to ingest data from Azure
Azure is Microsoft’s cloud solution, and, as such, it’s built to be Windows-friendly and SQL-server-friendly. The reality is that, if you’re working within an enterprise that has invested in Microsoft technology, you’ll likely find yourself working with Azure.
Accordingly, most data ingestion from Azure is looking to populate SQL server appliances or Windows servers to maintain environmental consistency. Azure has a built-in, one-click data ingestion wizard that can be helpful in these straightforward and limited scenarios.
However, if you’re planning to use ingestion for frequent or continuous data replication (meaning you’ll need more than a one-off ingest), or if you’re planning to populate an environment that’s not Microsoft-friendly, you’ll need to look at additional tools.
Our SQDR software can easily facilitate Azure ingestion to virtually any destination – Microsoft or non-Microsoft.
How to ingest data from Amazon Web Services (AWS)
Traditionally, AWS has been a great place to dump data.
The platform provides efficient SW3 storage and makes it easy to get access to relational data without requiring the price tag of most proprietary environments (like Microsoft SQL server, Db2, or Oracle) – although you can still host proprietary databases on AWS.
Many enterprises, though, treat AWS like a salt mine: They put data in to meet archival requirements, but the data they deposit is not incredibly well organized, and the general hope is that it doesn’t need to be accessed often (or at all).
This can make data ingestion from AWS a bit more complicated. Here, too, SQDR can help to structure ingestion in a way that makes data usable for any heterogeneous replication.
Ready to get started with data ingestion?
Hopefully, the information offered above has been helpful in giving you a fuller understanding of data ingestion. If you’re considering implementing a data ingestion pipeline in your organization, the next question is: How can you get started?
The first step is simple: Get in touch with us.
Whether you need data ingestion for predictive analytics, data ingestion for business intelligence, or data ingestion for client reporting, you deserve data you can rely on and service from a team you can trust.
We’ve provided industry-leading data solutions for over 20 years. Our solutions don’t require any programming, and our customer service team is awesome – our clients call it “the best vendor support I have ever encountered.” If you have enterprise data ingestion needs, let’s talk.
The companies that win the next decade will do so on the wave of big data. We’d love to help you successfully navigate the ride.
Schedule a free demo, and we’ll work with you to model out what data ingestion using StarQuest Data Replicator (SQDR) software could look like in your environment using the DBMS of your choice.