

Enterprise organizations create huge amounts of data. Data replication allows for that data to be used strategically, without compromising the application systems that produce it.
At StarQuest, we provide enterprise organizations like US Foods, Mazda, and AmerisourceBergen with real-time data replication, migration, and ingestion for databases, data warehouses and big data platforms. If you’re searching for an easy, cost-efficient, and reliable data replication solution for your enterprise, get in touch with us to see a no-charge demo of the StarQuest Data Replicator (SQDR) software using your DBMS of choice.
If this all sounds a bit confusing, don’t worry. On the rest of this page, we’ll provide a comprehensive overview of data replication. We’ll work from a high-level to outline the concept itself, then dig into some of the specific requirements for data replication types.
We’ll cover topics like:
- What does data replication mean?
- What’s the difference between database replication and database mirroring?
- What are common types of data replication?
- What is snapshot replication?
- What is transactional replication?
- What is merge replication?
- How does real-time data replication work?
- How does data replication help with disaster recovery?
- What are the top data replication tools?
- Data replication overview:
- How to get started with data replication
By the end, you should have a high-level understanding of data replication and first steps toward implementation in your context.
If you’re ready to implement data replication for your context now, reach out. If you’re ready to learn more, keep reading.
What does data replication mean?
Let’s start by offering a definition of data replication.
IBM offers a basic definition: “Replication is the process of copying data from a central database to one or more databases.”
At a fundamental level, data replication is exactly what the term suggests: the copying of data. But, practically, it involves a lot more than copying.
Here’s how TechTarget explains the concept in more detail:
“Database replication is the frequent electronic copying of data from a database in one computer or server to a database in another — so that all users share the same level of information. The result is a distributed database in which users can quickly access data relevant to their tasks without interfering with the work of others.”
This encapsulates two of the key factors that enterprise organizations associate with data replication: frequency and distributed access.
First, data replication implies frequency.
In other words, in replication, data usually isn’t being copied one time and left to sit (although there are use cases where data replication is comparatively infrequent). Most often, data replication involves data being updated frequently – every day or hour or transaction – to maintain integrity and value.
Second, data replication implies distribution.
Data is replicated for a purpose, and one of the most common purposes is to reduce the load on application servers. If data is updated frequently, queries can be run on the distributed servers, allowing the application server to remain dedicated to application processes. Data replication does not refer to data that’s copied to the same server; usually, data replication sends copies to a distributed network of servers.
Reasons for Data Replication
With these things considered, we can flesh out our definition by offering the most common use cases for data replication. As Brian Storti correctly outlines, these are:
Data replication to minimize travel time.
Take, for example, a global enterprise that has offices in Asia and in the US. They have a database in the US that’s being replicated to a database in Asia. When the customer service team in Asia goes to access data, they are able to query the database in their region.
If they were forced to query the database in the US, they’d experience a lag as the request traveled back and forth, potentially hindering their ability to offer live service.
Data replication to scale the capability to serve requests.
Take for example a global enterprise with offices in both Asia and the US, they rely on a database to log customer transactions. This database is being replicated to a second database. When a customer service representative is asked to look up the details of a transaction, they do so by querying the second database. This way, the database that is actively logging transactions is unaffected.
Without data replication, the customer service rep would have no other choice but to query the customer transaction database, potentially slowing it down and compromising its ability to function.
Data replication for disaster recovery and business continuity.
Perhaps the simplest use case for data replication is to have another instance of data in case a server goes down. Because data replication implies frequency, applications may even be able to access the replicated data without any downtime.
For example, if a SaaS company has a production server fail, they can keep services running without interruption by having a business continuity solution in place.
Data replication for testing environments.
Finally, data replication is helpful for test environments where it’s necessary to access up-to-date data, but where additional demands on a live application server are unwanted. For example, if an enterprise is testing out a new ticketing system, it might be helpful for them to do so with real data, but they likely won’t want to add additional requests to their live system. Data replication can solve this challenge.
What’s the difference between database replication and database mirroring?
With database replication defined, let’s tackle a common question: How is it different from database mirroring?
To start, database mirroring is a term coined by Microsoft. It’s used by Microsoft’s SQL server, but it can also be done on other database management systems.
According to the definition of data replication as we’ve laid it out above, database mirroring is a form of data replication in that it involves the creation of redundant copies of a database on a separate server.
There are two key differentiators, though. First, database mirroring involves the replication of the entire database as a whole. That means that it includes the replication of protocols, schema, security credentials, program extensions, and more. This can only be done in homogeneous environments – that is, you couldn’t mirror an Oracle Database to a SQL Server. In standard data replication, on the other hand, replication is done on specific database objects. You could use replication to make copies of a specific table, for example, and you could store that replicated data on a different DBMS.
Second, mirroring usually doesn’t allow for access to the redundant copy unless the master database goes down. In other words, mirroring is usually used for high availability disaster recovery as opposed to the other use cases we’ve discussed for data replication.
What are common types of data replication strategies?
With that clarified, let’s take a look at the different types of data replication.
Snapshot Replication
Snapshot replication essentially takes a snapshot of data from the source database at a moment in time, and then replicates that snapshot to the destination server. This method is a bit slow, because it moves all records at once. It also doesn’t monitor for updates to data.
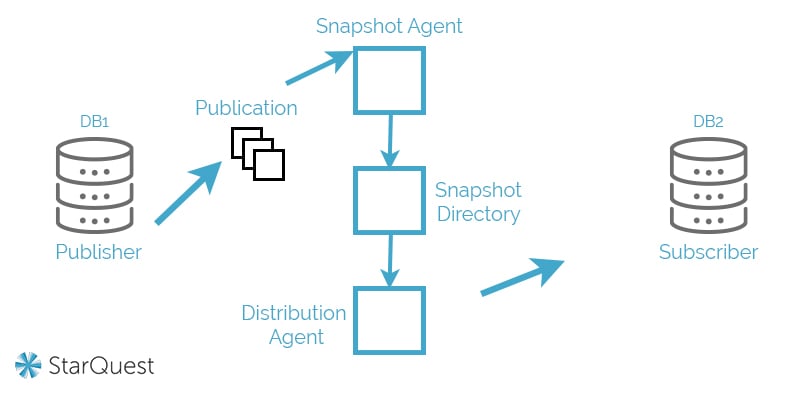
Consequently, it’s generally best used when data changes are infrequent or when performing initial synchronization between the source and the destination server. For example, let’s say a publisher (primary / source server) houses transaction data and data replication hasn’t been implemented yet. To begin data replication, you could perform snapshot replication of the publisher. Then, as updates were made, you might use…
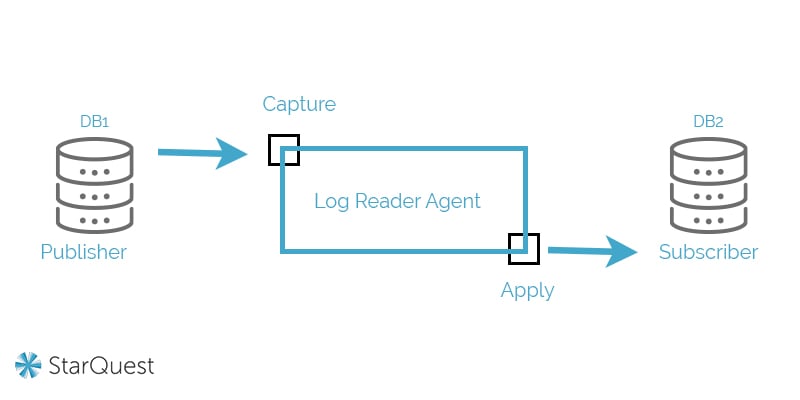
Transactional Replication
Transactional replication is better for real-time accuracy. It involves a copy of the database (subscriber) that’s modified as the publisher changes. This keeps data up-to-date and accurate. It’s most common in server-to-server environments where real-time fidelity is crucial.
Merge Replication
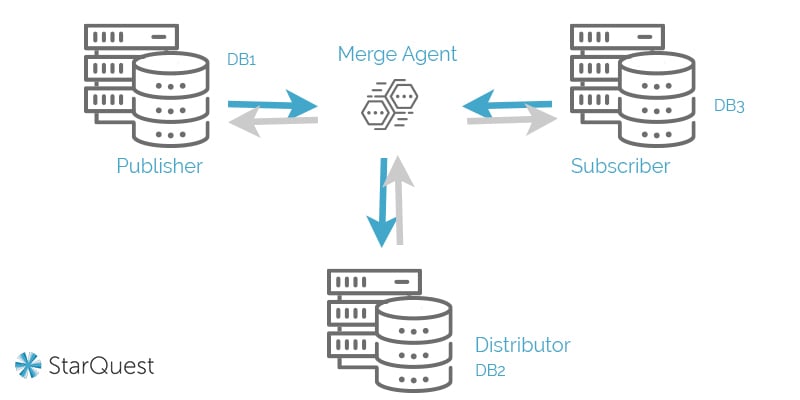
Finally, merge replication involves the merging of multiple databases into a singular database. This is regarded as the most complex type of data replication, and it’s most common in server-to-client environments.
For example, if the transaction database we referenced in our snapshot replication illustration was also impacted by customer service data from another database, it might make sense to use merge replication to generate a singular (authoritatively accurate) database.
How does real-time data replication work?
We’ve touched on real-time data replication on our blog, but let’s dig into it in more detail – because, for many data replication use cases it’s a necessity.
What Does “Real-Time” Mean?
At a bottom-line level, real-time data replication means that, when data from the replicated database is accessed, it is representative of the current publisher data.
To illustrate: Let’s say that an enterprise has a database of transaction data that’s being replicated for access by the customer service team. When a customer calls in with a question and the customer service rep checks the destination server where data is being replicated, they should see the customer’s data as it’s represented in the publisher. In other words, the customer service rep shouldn’t have the wrong information.
Real-time data replication does not mean that data is literally replicated at the same time it’s published; there has to be some delay, however slight. (If there is no delay, then data is being simultaneously published in multiple places, not replicated.)
So, determining what real-time means in your use case requires understanding how often data needs to be accessed. If you’re using data replication for end-of-day reporting, for example, then real-time data replication could refer to snapshot replication that happens at the close of a business day.
The Most Common Method of Real-Time Replication
Most commonly, though, data replication that’s considered to be real-time is done through transactional replication, where changes to records are updated to the subscriber databases as soon as they’re made in the publisher.
How does data replication help with disaster recovery?
As mentioned previously, one common data replication use case is for disaster recovery.
At a fundamental level, data replication for disaster recovery is pretty straightforward: Replication allows for redundancy. If a publisher goes down, the subscriber(s) can be accessed with minimal (or hopefully no) lag time.
If data replication is being used for a disaster recovery solution, there are a few considerations to make:
How Up to Date Must the Replicated Data Be to Be Valuable?
Having day-old data may be no problem if data is only updated every day. For most enterprise applications, though, in order for disaster recovery to be effective, data replication should have something closer to minute-by-minute accuracy.
What Will Access of the Subscriber Database Look Like in the Event of a Disaster?
This is where the rubber meets the road. In the event of a disaster, having replicated data does no good if it can’t be accessed. As your organization designs a disaster recovery solution, consider what the recovery part of the solution will look like. Will clients be expected to access the subscriber database for an extended period of time? Will failure designate the subscriber to become the new publisher?
At a business level, of course, the idea is to minimize the potential for workflow disruption if your primary servers go down.
What are the top data replication tools?
Before we get into the specific database replications that enterprises commonly pursue, let’s stay at a higher level and take a look at some software tools that enable data replication.
1. StarQuest Data Replicator
Admittedly, we might be slightly biased, but we believe that our data replication software is the best on the market for a variety of enterprise needs.
Star Quest Data Replicator (SQDR) sits between source and destination databases, allowing for real-time replication, vendor agnostic heterogeneous DBMS pairings, and relational and NoSQL database compatibility using an intuitive graphical user interface (GUI).
Notably, SQDR has a near-zero footprint on production servers. It’s also built to automatically restore replication following connectivity loss, without processes being compromised (something that’s a struggle for many other solutions).
Finally, SQDR typically allows for cost-savings of up to 90% when compared against our competitors. This is due to our per-core pricing model and our tailored implementations that are designed to meet your requirements, not to sell you services you don’t need.
To learn more about how SQDR can serve your organization’s data replication requirements, get in touch with us to schedule a free demo.
2. IBM InfoSphere Data Replication
Nobody has ever gotten fired, the saying goes, for hiring IBM; the company is always, at the least, a safe choice. As you might expect from one of the world’s leading computing firms, their data replication product – InfoSphere – is a solid option.
Here’s how IBM describes the platform:
“IBM InfoSphere Data Replication provides log-based change data capture with transactional integrity to support big data integration and consolidation, warehousing and analytics initiatives at scale.”
It works for heterogeneous database pairings and is built for continuous availability. It’s a robust solution for enterprises, but if you’re looking for cost-efficiency, you may want to look elsewhere – it does, unsurprisingly, carry an enterprise-level price tag.
3. Oracle GoldenGate
Oracle is another Fortune 500 firm that’s well known for offering reliable computing solutions. Their solution in the data replication space is Oracle GoldenGate. Here’s how the company describes the solution:
“Oracle GoldenGate is a comprehensive software package for real-time data integration and replication in heterogeneous IT environments. The product set enables high availability solutions, real-time data integration, transactional change data capture, data replication, transformations, and verification between operational and analytical enterprise systems.”
Obviously, GoldenGate’s biggest benefit is its tight integration with Oracle Database, but it is built for heterogeneous data transfer. Like IBM, Oracle is a worthwhile solution to consider if cost-efficiency isn’t a high priority.
4. HVR Software
HVR Software is a newer solution. Originally, the company specialized in Oracle database replication, but the solution has grown to encompass all of the industry-standard platforms (which you can view on their homepage). Here’s how they describe their capabilities on their website:
“[It’s] everything you need for efficient high-volume data replication and integration, whether you need to move your data between databases, to the cloud, or multi-cloud integration, into a data lake or data warehouse.”
If you’re considering investing in a simple data replication option that’s optimized for cloud environments, HVR Software may make your list.
5. NAKIVO
NAKIVO is a bit of a newer player in the data replication space. Founded in 2012 and headquartered in Nevada, the company has grown to encompass a broad range of data management solutions.
Their offering, delivered via a web interface, is branded as: “Robust data protection for your virtual, physical, cloud and SaaS environments.” The solution involves more than data replication; they also offer features like failover, backup to the cloud, and backup to tape.
In terms of data replication, they are actually a bit limited in terms of what they can handle. They offer VMware replication, Hyper-V replication, and AWS EC2 replication.
6. Qlik Replicate
Qlik is another company that, while not as widely recognized as IBM or Oracle, has developed some name recognition for its data management offerings. The company bought Attunity Replicate several years ago, and now offers that solution under the brand name Qlik Replicate.
Here’s how they describe its capabilities:
“Qlik Replicate empowers organizations to accelerate data replication, ingestion and streaming across a wide variety of heterogeneous databases, data warehouses, and big data platforms.”
The product is one of a suite of tools (including Qlik Sense, Qlik View, Qlik Compose, and more) that the company offers. Like tools offered by IBM, it can be effective, but it’s not known for its cost-efficiency.
Data Replication Considerations for Different Database Types
Finally, let’s review some of the factors to consider when replicating some of the most common database types.
SQL Server Replication
SQL Server is a Microsoft product, which means that it’s very standardized, pretty easy to work with, and a bit limited in its integration with other environments. It is a relational database.
Notably, SQL Server doesn’t allow direct log access; instead, the environment is designed to provide a queryable version of the log information. This results in some limitations, because not all data is exposed for replication.
Another thing to note with SQL Server is that it is increasingly viewed as a legacy database. It’s still widely used, of course, but data is more often replicated from SQL Server to a different, cloud-based environment than it is replicated to SQL Server.
Oracle Database Replication
Oracle Databases are the gold standard of transactional databases, they’re extremely well-built and standardized, and they’re also very expensive.
Additionally, Oracle is somewhat notorious for creating products and environments that lead to vendor lock-in. Once you get onto an Oracle platform, it’s difficult to get off.
IBM Db2 Replication
IBM is another industry standard database type, and, like Oracle, it’s known for being robust and expensive. Db2 is built on a common SQL engine, and, like Oracle, is designed for scalability and flexibility.
IBM and Oracle are two great choices if you’re planning to process vast amounts of data. They aren’t great choices if you’re looking to be cost-efficient.
PostgreSQL Replication
There are a variety of similar open-source DBMS platforms (PostgreSQL, MySQL, MongoDB, etc.). We’ll cover PostgreSQL here, but the items below are, for the most part, applicable to other platforms as well.
PostgreSQL is a newer platform that plays well in cloud environments. Its big benefit is that it is very cost-effective. Relatedly, there’s no risk of vendor lock-in, and there are a wide variety of third-party tools that are built to interface with it.
However, because it’s open source, it’s also far less standardized than the other database types listed here. That means that creating a robust and reliable data replication solution can take more work.
How can you get started with data replication?
Hopefully, this information has been helpful in giving you a fuller understanding of data replication. If you’re considering implementing data replication for your organization, the next question is: How can you get started?
Whether you need data replication for disaster recovery, data replication for a testing environment, or data replication for increased systems performance, you deserve data you can rely on and service from a team you can trust.
We’ve provided industry-leading data solutions for over 20 years. Our solutions don’t require any programming, and our customer service team is awesome – our clients call it “the best vendor support I have ever encountered.” If you have enterprise data replication needs, let’s talk.
Schedule a no-charge demo, and we’ll work with you to model out what data replication using StarQuest Data Replicator (SQDR) software could look like in your DBMS of choice.